
AWS Serverless Cloud Consultant
Building scalable, cost-effective serverless solutions with AWS Lambda, DynamoDB, and modern cloud technologies
Let's Work Together
35+ Articles on AWS & Serverless
Building scalable, cost-effective serverless solutions with AWS Lambda, DynamoDB, and modern cloud technologies
Let's Work TogetherWhether you're migrating to serverless or training your team, I'll help you succeed with AWS
Migrate your applications to AWS Lambda and serverless architecture for improved scalability and reduced costs
Hands-on training for your team on AWS serverless services and best practices
Specialized in AWS serverless architecture, infrastructure as code, and automation

AWS Lambda
AWS
DynamoDB
AWS
S3
AWS
API Gateway
AWS
EventBridge
AWS
Step Functions
AWS
SQS
AWS
CloudFormation
AWS
AWS CDK
ToolTypeScript
LanguageNode.js
LanguageJava
LanguageSharing knowledge from building serverless applications on AWS
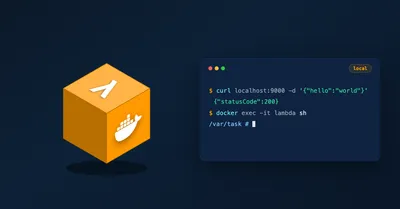
Run AWS Lambda container images on your machine with the Runtime Interface Emulator. Build the image, pass IAM or AWS SSO credentials, verify them with STS, and shell into the container to debug.
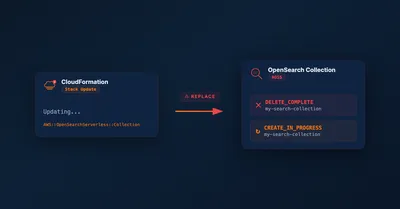
AWS::OpenSearchServerless::Collection requires replacement when you update tags — a surprising CloudFormation behavior that can break cross-account setups and cause downtime.

How to set up OpenSearch Serverless for cross-account data ingestion using AWS CDK, VPC endpoints, and IAM role assumption — filling the gaps in AWS documentation.
Ready to migrate to serverless or train your team on AWS? Get in touch and let's discuss how I can help.
Available for consulting projects and workshop bookings